
A few weeks ago, we promised a post that would publish the OpenBrain architecture diagram and explain, in concrete terms, how the platform connects to existing telephony without replacing any of it.
If you read the procurement piece, you already know the constraint we were working against. Every voice AI vendor of the last funding cycle walked into the buyer’s meeting asking for some version of “replace what works.” The architecture below is the answer to “what if you don’t have to.”
We’ll walk through three things: what OpenBrain is in architectural terms, where it sits relative to your existing PBX, and what the call flow looks like when a customer dials your number.
What OpenBrain actually is
OpenBrain is a modular, microservices-based voice AI platform. It is not a contact center replacement. It is not, strictly speaking, an IVR replacement either. It is a layer that sits between your telephony and your AI capabilities, orchestrating the conversation while your phone system keeps doing everything it already does.
The platform operates in two layers.
At the telephony layer, OpenBrain communicates with your existing Private Branch Exchange over standard SIP signaling. SIP handles call setup, routing, and session control. The audio itself moves over RTP in full-duplex channels, exactly the way your PBX already speaks to every other endpoint. Nothing here is proprietary. Whether your PBX is Avaya, Genesys, NICE, Cisco, or a cloud-native equivalent, it already knows how to talk to a SIP endpoint. OpenBrain just becomes one of them.
At the application layer, the conversation itself happens over HTTP, with asynchronous messaging coordinating the services behind it. The speech-to-text engine, the language model, the text-to-speech synthesizer, the knowledge base, the conversation designer, the supervision panel — these all communicate through HTTP APIs. This is the layer where AI work happens. It is also the layer where we keep our complexity, so your IT team doesn’t have to.
The reason for the layering is simple: telephony is a solved problem with thirty years of standards behind it. We wanted to plug into that solved problem, not rebuild it.
Where OpenBrain sits
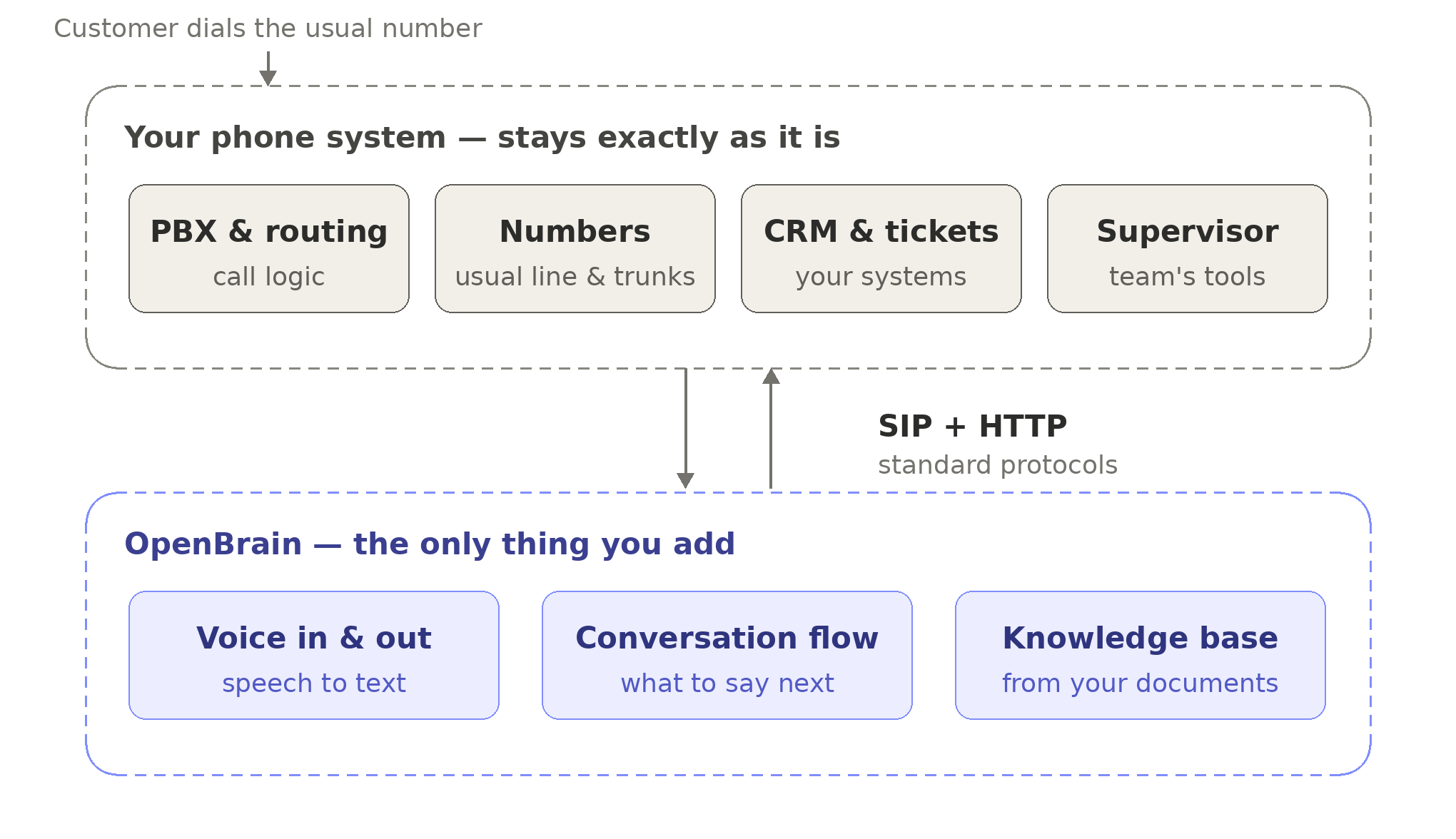
Your phone system stays exactly as it is. OpenBrain slots in underneath, and the only thing crossing the boundary is standard SIP and HTTP.
Reading the diagram top to bottom: a customer dials their usual number. The call lands on your existing PBX. Your PBX, using routing rules you already have, forwards it over a SIP trunk to OpenBrain. The platform takes over the audio, orchestrates the rest — transcription, the language model, the response, the speech synthesis — and streams the reply back through the same channel the caller is listening on.
Everything above the line is yours. Everything below it is OpenBrain.
On your side, nothing changes: your numbers, your trunks, your routing logic, your CRM connectors, your supervisor consoles, your reporting integrations. The phone system you spent years getting right keeps working exactly the way it does today.
On our side, you get the full stack: the AI services, the visual conversation designer, the knowledge bases, the analytics dashboard, and the supervision panel for AI conversations. We bring all of that. You don’t source any of it separately.
The integration surface between the two sides is a SIP endpoint and an HTTP webhook. That is the entire interface.
What happens during a call
Let’s trace a real one. In our healthcare deployment, a patient dials the clinic’s main number to reschedule a follow-up appointment.
The PBX answers and forwards the call to OpenBrain over SIP. The platform sets up the audio channels and initializes the conversation. It plays the welcome message — pre-synthesized in the project’s brand voice — and emits a short beep to indicate the patient may speak.
The patient says something like “I’ve been getting headaches for the past week and I’d like to see someone about it.” The audio is captured, run through the speech-to-text model, and the transcript is forwarded to the conversation logic engine. Rather than asking the caller to navigate a menu of departments, it interprets what they actually said: it recognizes the symptom, draws on the clinic’s own knowledge base to map it to the right specialty, and responds with a question — “That sounds like something a neurologist would handle. Would you like me to set up a consultation with neurology?” The response, in text, is synthesized into speech and streamed back over the same channel the patient is on.
The conversation loops like this until the AI either resolves the call end-to-end or decides a human is needed. If a human is needed, the call returns to your PBX with full context, and the agent picks up where the bot left off.
And if anything fails along the way — a model timeout, a network glitch, anything outside expected behavior — the call is transferred to a human agent automatically. The customer is never stranded.
Why this architecture survives procurement
The economics of the deployment follow directly from the architecture. Your contact center isn’t being migrated. Your numbers aren’t being ported. Your CRM isn’t being re-integrated. Your supervisor team isn’t being retrained on a foreign console. The only thing actually changing is what answers the call after your routing logic sends it to AI.
OpenBrain runs in your own data center, on Kubernetes, on GPU workstations, or in a cloud region you control. For organizations with data residency requirements — which covers most of healthcare and a substantial part of telecom — running the entire AI stack on-premise is supported out of the box. Nothing leaves your perimeter unless you choose to send it.
The next post moves up one layer and walks through the visual designer — where the actual conversations get built.







